Commentary
Media, actors, authors challenge AI over IP rights
News organizations have started blocking at least some AI web crawlers, related to concerns about intellectual property. We take a deep dive into the technology (and the IP issues) at stake, along with exploring potential solutions.

September 26, 2023 by Daniel Brown — Editor, Networld Media Group
 ChatGPT
ChatGPT Grok
Grok Perplexity
Perplexity Claude
ClaudeNearly one-third of the world's largest news sites have blocked AI crawlers out of intellectual property concerns, according to a press release and report from AltIndex (using data from Kirwan Digital); publications including CNN, New York Times, Daily Mail, Reuters and Bloomberg were all listed as blocking at least one of the major AI crawlers.
So, what is an AI crawler, and why are content creators worried about AI and copyrights? Today, we take a deeper look under the hood of AI systems like ChatGPT, including expert interviews, to understand the technology and the backlash it has inspired in some quarters.
Under the hood of an AI
To get a better understanding of the AI and web crawler technology, I interviewed Miguel Orozco-Quime, IT director at Roots to Recovery, via video link on Wednesday. Orozco-Quime's specializations include software programming and AI, with a focus on the healthcare space.
"Large language models essentially take in so much data — you feed it a corpus of text, and it learns off of it ('learning' in quotes')," Orozco-Quime said, adding that while some experts claim that the technology is little more than a glorified predictive text system, but some would argue the same of human cognition.
While we aren't yet at the place of fully sentient AI, commonly called Artificial General Intelligence (AGI), he says that is coming sooner than we think; still, with experts disagreeing on the definition of consciousness and terms like "learning" and "reasoning" in humans, it's hard to define those terms for AI.
"How does the brain work? It's essentially doing a similar kind of task — we're just able to consume so much more information from visual and other stimuli or memory — and that's another thing to consider, memory," he added. " Those large language models don't have the memory capacity that a human does; so it seems like, after a certain point, the system tends to fall off, like it doesn't really understand what it's spitting out anymore. At that point, when you go outside of its context window, it's a little bit harder for it to remember what it said even 1000 words ago."
Similar to the web crawlers that search engines like Google use to catalog and categorize all the data on the Internet, an AI crawler studies all the publicly available data on the Internet to find patterns and help it understand user queries better.
Orozco-Quime said he no longer uses regular search engines in his web searches (except for certain up-to-the-minute info like menus or business hours) because GPT works so much better, and at work, he has used AI to help augment his programming work and says he has been impressed by the GPT experience, noting that the system has about the intelligence of a junior-level human programmer, which he says is pretty impressive. He has also used Microsoft CoPilot, an AI-powered coding assistant tool, to augment his programming work.
And that is the key, Orozco-Quime argues; AI isn't meant to replace human work, whether in programming or creativity; it's meant to augment that work, to enhance what humans are able to do.
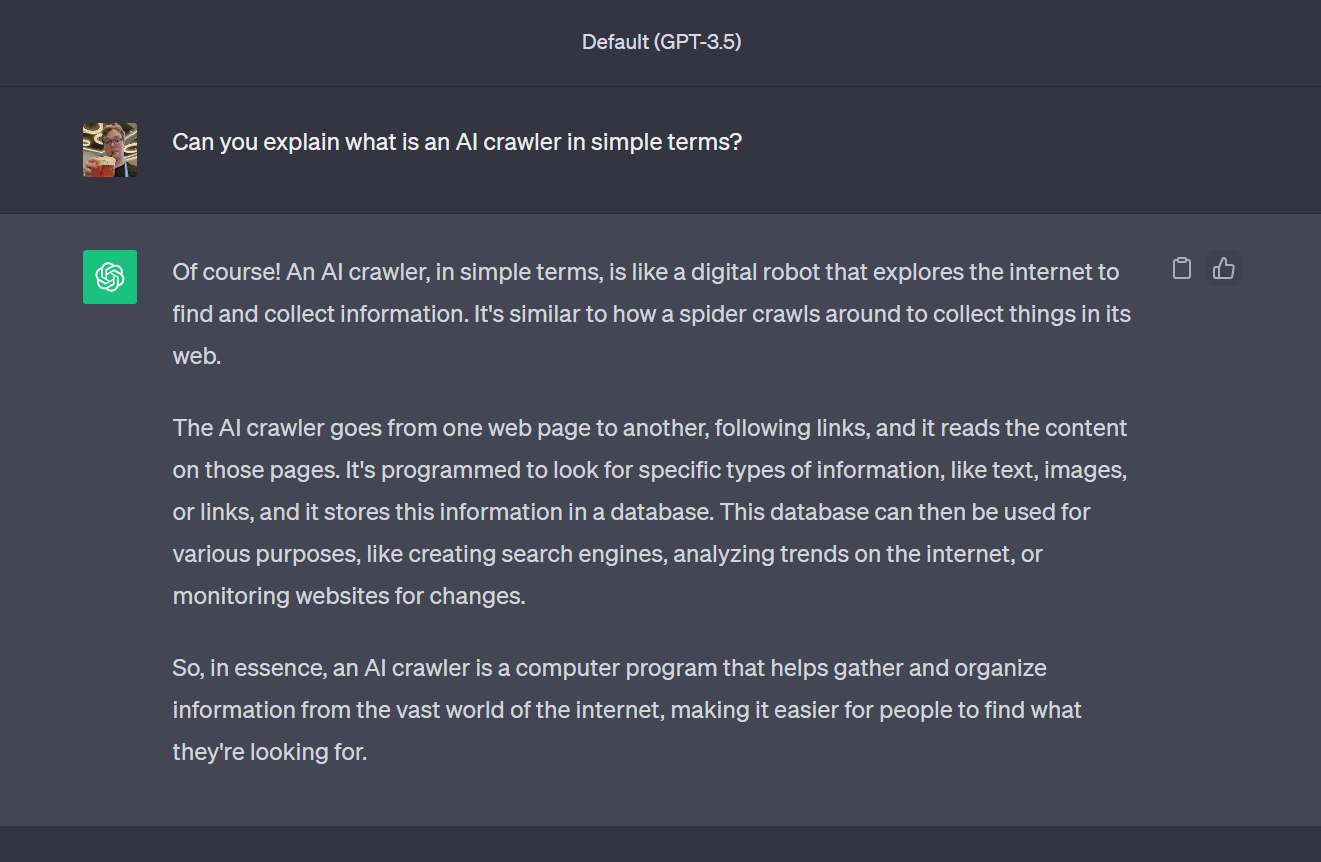 |
A screenshot of how ChatGPT explains web crawlers to me in simple terms. Image: Daniel Brown/Networld Media Group. |
Text, IP, Privacy concerns are mounting
The blocking of AI crawlers by some news organizations comes on the heels of other IP-related concerns and even legal actions that have emerged as generative AI tools like ChatGPT have become widely used.
Sarah Silverman filed a lawsuit against OpenAI (the parent company of ChatGPT) and Meta for copyright infringement, according to a report from The Verge. Authors Christopher Golden and Richard Kadrey were also named in the lawsuit. Similarly, authors Paul Tremblay and Mona Awad have filed a lawsuit, including allegations of copyright infringement and violation of the Digital Millenium Copyright Act by OpenAI related to ChatGPT.
But it's not just writers and actors who are concerned; photography and images are another area of concern, with Getty Images suing Stability AI, which develops generative AI for visual content, according to a report from the European Commission's IP Helpdesk (an official arm of the European Union).
Privacy is another concern, with a federal class action lawsuit filed in California this June against OpenAI, according to a report from Computer World; the complaint in part alleged that "OpenAI used the stolen data to train and develop [ChatGPT] utilizing large language models … and deep language algorithms to analyze and generate human-like language that can be used for a wide range of applications," according to the report.
Microsoft was also named as a defendant in that lawsuit, according to a report from CNN Business. "By collecting previously obscure personal data of millions and misappropriating it to develop a volatile, untested technology, OpenAI put everyone in a zone of risk that is incalculable — but unacceptable by any measure of responsible data protection and use," Timothy K. Giordano, an attorney at the firm behind the legal action, said to CNN in the report.
SAG-AFTRA and the Writer's Guild of America have also voiced concerns about generative AI and intellectual property issues, including statements from union members during recent high-profile strikes. From worries about an actor's image, voice, and individual characteristics being "owned" and used by studios without consent or payment, to concerns about copyrighted materials being used to train AI models without the consent (or payment) of authors or copyright holders, Hollywood has raised public consciousness of one of the unintended consequences of the AI hype cycle. For example, a USA Today report quoted Breaking Bad star Bryan Cranston's stance on the issue: "We will not be having our jobs taken away and given to robots. We will not allow you to take away our dignity."
Breaking Bad star Bryan Cranston speaks on AI while at a picket line during the current actors' strike. Video credit: AP. |
Time will tell
With generative AI being rapidly adopted across industries for nearly every kind of workflow imaginable, it's unlikely that the technology is going away. However, due to the strong reactions from high-profile individuals and industries against the way AI is built, trained, deployed and used, there needs to be an urgent discussion in how we regulate and deploy AI in a way that benefits content creators and users alike.
"What's behind the curtain of AI? The cost of the human labor it took to produce the training data," wrote actor Joseph Gordon Levitt in an opinion piece in the Washington Post. "'Generative AI' cannot generate anything at all without first being trained on massive troves of data it then recombines. Who produces that training data? People do."
Ironically, AI and other emerging technologies may hold the solution to this very problem, Levitt argues, suggesting an AI-powered residuals system to compensate humans when their creative products have been used in some way by a generative AI.
"So, here's my request: Residuals from AI training data should be made mandatory and intellectual-property law amended to make sure those residuals go to the people who deserve them. The seemingly miraculous outputs of generative AI should not be allowed to fill the coffers of tech giants or any other giants without paying the people whose data made those outputs possible."
Joseph Gordon-Levitt speaks about his op-ed for the Washington Post. Video credit: Washington Post. |
So, what is the solution?
With similar concerns in the music industry, some creatives are proposing the use of blockchain to facilitate such a system. For example, consider the recent Elf.Tech experiment by Canadian artist Grimes, in which users can use open-source Grimes content along with generative AI to make their own Grimes-style content. In return, users are expected to use the open-source content tastefully and to share 50% of royalties from the hybrid creations, as reported by Fortune. The idea is to use so-called "smart contracts" (which are powered by blockchain) to ensure fair and proper compensation (with tracking enabled by the blockchain ledger).
On the image front, some companies have been proactive to guard against IP-related risks; for instance, the Adobe Firefly generative AI system was designed from the start to compensate artists and models whose work is used by the AI in creating art; still, without external pressure from government, consumers, or industry collectives, it's hard to imagine every company being so cautious in the current AI arms race.
And on the tech front, Orozco-Quime said the world could take a page from Japan's book, with an approach that views the Internet as a public space, and that the current model of AI web crawlers are merely accessing the same kind of public information that older, more primitive search engines access; they just do it in a more intelligent way.
While he's sympathetic to the anxieties of artists and creators, he suggests the tech, when understood at a deep level, isn't actually violating copyright as long as it isn't being used to copy existing work, nor does he see a threat to human creativity. "People say stuff like, 'ChatGPT will replace programmers or engineers — I mean, I do that stuff for a living, but I'm not really threatened by it. I see these tools as an augmentation to myself.
"From what I'm seeing with AI, I think the problem is that you shouldn't be using it to replicate someone's work, like with the actors and writers and so on. If you're not actively copying someone's work, but you use their work to help influence your own work, I don't see that as a bad thing. I mean, you read stuff online, and that influences what you write. It's the same thing with artists; artists start off copying stuff that's in galleries, and then they do their own work. I see those in basically the same way."
"If we don't know what we want, we're unlikely to get it"
With such a chaotic revolution affecting virtually every aspect of modern work and life, thanks to generative AI, it's not yet clear what (if any) regulatory framework will emerge, but one thing is clear. Content creators and consumers (and companies representing their work) need to be engaged proactively in this ongoing conversation. In Life 3.0, his landmark manifesto on the A.I. age, physicist and futurist Max Tegmark argues that with so many unknowns, the one thing we do know as citizens is that each of us bears a responsibility to get involved in the conversation about how we as a species choose to shape this pivotal moment in our planet's history.
"In terms of what will ultimately happen, you'll currently find serious thinkers all over the map: some contend that the default outcome is doom, while others insist that an awesome outcome is virtually guaranteed," Tegmark wrote. "To me, however, this query is a trick question: it's a mistake to passively ask 'what will happen,' as if it were somehow predestined!"
"If a technologically superior alien civilization arrived tomorrow, it would indeed be appropriate to wonder 'what will happen' as their spaceships approached, because their power would probably be so far beyond ours that we'd have no influence over the outcome," Tegmark added. "If a technologically superior AI-fueled civilization arrives because we built it, on the other hand, we humans have great influence over the outcome — influence that we exerted when we created the AI. So we should instead ask: ' What should happen? What future do we want...' Only once we've thought about what sort of future we want will we be able to begin steering a course toward a desirable future. If we don't know what we want, we're unlikely to get it."
 |
My personal (and heavily annotated) copy of Max Tegmark's Life 3.0, with the cited quote on page 159. Image credit: Daniel Brown/Networld Media Group. |
About Daniel Brown

Daniel Brown is the editor of Digital Signage Today, a contributing editor for Automation & Self-Service, and an accomplished writer and multimedia content producer with extensive experience covering technology and business. His work has appeared in a range of business and technology publications, including interviews with eminent business leaders, inventors and technologists. He has written extensively on AI and the integration of technology and business strategy with empathy and the human touch. Brown is the author of two novels and a podcaster. His previous experience includes IT work at an Ivy League research institution, education and business consulting, and retail sales and management.
More From CommentaryMore
Related Media
Subscribe
Get the latest news and resources from Automation & Self-Service.





